BAIN?!
Fragen und Antworten zu Bibliotheks- und Archivinformatik
Tag 10
by K.K.Buhler
LINKED DATA, BIBFRAME & RIC
Was ist Linked Data?
Aus einer kurzen Internetrecherche lässt sich Linked Data so zusammenfassen: Linked Data sind miteinander verlinkte strukturierte Daten. Die veröffentlichte Verlinkung macht die Daten aussagekräftiger und dadurch sehr nützlich. Sie erleichtert Entwicklern die Verbindung von Informationen aus unterschiedlichen Quellen, was zu neuen und innovativen Anwendungen führt. So sind beispielsweise semantische Abfragen möglich, aus denen Schlussfolgerungen abgleitet werden können. Linked Data baut auf Webtechnologie wie HTTP, RDF und URIs, nutzt diese aber nicht nur für visuell lesbare Webseiten, sondern erweitert die geteilte Information so, dass sie auch maschinenlesbar ist.
Das World Wide Web Consortium (W3C) sagt es so:
Linked Data lies at the heart of what Semantic Web is all about: large scale integration of, and reasoning on, data on the Web.
Was ist Open Data?
Antwort von Wikipedia:
Als Open Data werden Daten bezeichnet, die von jedermann zu jedem Zweck genutzt, weiterverbreitet und weiterverwendet werden dürfen. Einschränkungen der Nutzung sind nur erlaubt, um Ursprung und Offenheit des Wissens zu sichern, beispielsweise durch Nennung des Urhebers oder die Verwendung einer Share-alike-Klausel.”
Und was ist Linked Open Data (LOD)?
Eine weitere Antwort von Wikipedia:
Linked Open Data bezeichnet im World Wide Web frei verfügbare Daten, die per Uniform Resource Identifier identifiziert sind und darüber direkt per HTTP abgerufen werden können und ebenfalls per URI auf andere Daten verweisen. Idealerweise werden zur Kodierung und Verlinkung der Daten das Resource Description Framework und darauf aufbauende Standards wie die Abfragesprache SPARQL und die Web Ontology Language verwendet, damit sie von Maschinen in ihrer Bedeutung richtig interpretiert werden können.
Die Zusammenfassung:
Und Ontotext fasst es so zusammen:
Linked Data is a set of design principles for sharing machine-readable interlinked data on the Web. When combined with Open Data (data that can be freely used and distributed), it is called Linked Open Data (LOD). An RDF database such as Ontotext’s GraphDB is an example of LOD. Linked Data is one of the core pillars of the Semantic Web, also known as the Web of Data. The Semantic Web is about making links between datasets that are understandable not only to humans, but also to machines, and Linked Data provides the best practices for making these links possible. In other words, Linked Data is a set of design principles for sharing machine-readable interlinked data on the Web.
Was hat Linked Data mit BAIN zu tun?
Im Zusammenhang mit Bibliotheks- und Archivinformationssoftware stellen Linked Data derzeit Zukunftsperspektiven dar. Entwicklungen wie BIBFRAME und RiC basieren auf Linked Data und möchten künftig ein mehrdimensionales Verständnis von Information vermitteln. Die Daten können mit Daten von anderen Institutionen verbunden, angereichert und verbessert werden.
Ist BIBFRAME das Zukunftsdatenmodell für Bibliotheken?
Ja, im Kontext der Bibliotheken wird BIBFRAME in Zukunft eine wichtige Rolle spielen. Mit der Anwendung des Datenmodells soll der Nutzen von Bibliothekskatalogen sowohl inner- als auch außerhalb der bibliothekarischen Community erhöht werden. BIBFRAME ist ein Datenmodell für bibliografische Daten. BIBFRAME wurde von der Library of Congress entworfen, um das Austauschformat MARC zu ersetzen und Linked Data-Prinzipien anzuwenden. Ausdrückliches Ziel der BIBFRAME-Initiative: “Es soll ein Rahmenkonzept geschaffen werden, das für eine Vielzahl heterogener Datenquellen genutzt werden kann und somit von Daten bereitstellenden Institutionen unterschiedlicher Sparten genutzt und interpretiert werden kann.”
Die Interessengruppe BibliothekarInnen Schweiz stellt sich dazu ebenfalls Grundsatzfragen: Bibframe - Was ist das, was hat das mit uns zu tun und wofür brauchen wir es? Eine Antwort aus dem lesenswerten Bericht ist: “In den letzten Jahren haben immer mehr Bibliotheken erkannt, welches Potential sich mit der Veröffentlichung ihrer Daten als Linked Data entfaltet. Die wertvollen, größtenteils intellektuell gepflegten bibliographischen Daten können nun für weitere Nutzergruppen zugänglich gemacht und Grundlage für die Etablierung neuer Services und Anwendungen werden. Die bisher bewährten bibliothekarischen Formate für den Datenaustausch können den Anforderungen nicht gerecht werden, die durch die immer stärkere digitale Vernetzung der Informationswelt entstehen.”
Die aktuelle Version BIBFRAME 2.0 basiert auf FRBR (Functional Requirements for Bibliographic Records). FRBR ist eine Empfehlung der International Federation of Library Associations and Institutions (IFLA) aus dem Jahr 1998, mit der Absicht, Katalog-Datenbanken zu restrukturieren und die konzeptuelle Struktur der Informationsressource zu reflektieren. FRBR definiert 4 Entitäten und RDA beschreibt diese. Dazu äussert sich die Interessengruppe so: “In BIBFRAME kommen nun die FRBR auf den Prüfstand. Die Fachleute mit BIBFRAME-Expertise besitzen größtenteils entweder Format- oder RDF-Expertise, und weniger Regelwerks-Expertise. Es geht langfristig um die Ablösung von MARC 21 und die Definition eines neuen Träger-Standards. FRBR scheint nicht einfach genug zu sein, um im Semantic Web nutzbar und interpretierbar zu sein. Schon die RDA haben z.B. die Möglichkeit eingebaut, die Expressions-Ebene zu umgehen und die Manifestation eines Werkes zu modellieren. Es gibt keine Eins-zu-eins-Entsprechung zwischen FRBR und BIBFRAME, oder zwischen RDA und BIBFRAME. Bei dem, was anhand der drei “RDA Database Implementation Scenarios” diskutiert wurde und wird, also den Optionen bei der Modellierung der Entitätentypen, von 3 (aktuell) über 2 (aktuell in Bibliotheken der deutschsprachigen Länder verbreitet) bis 1 (ideal), wird nicht immer klar unterschieden, ob sie wirklich für die Kommunikation (den “Austausch” oder die “Repräsentation” der Daten) gedacht sind, oder ob sie sich nicht eher auf die interne Implementierung beziehen. Noch eine vielleicht überspitzte Formulierung: FRBR sind ein Entity-Relationship-Modell, wohingegen BIBFRAME ein Relationship-Entity-Modell ist: Der Wert eines Knotens im Geflecht bestimmt sich danach, wie viele Fäden zu ihm hinführen.”
BIBFRAME besteht aus zwei Elementen:
-
Das BIBRRAME Vocabulary definiert Konzepte und deren Eigenschaften und beschreibt die Entitäten des Datenmodells.
-
Das Bibframe-Modell, ein Überblick zum Datenmodell, beschreibt die drei Abstraktionsebenen “Work, Instance, Item” und die drei Hauptklassen “Agent, Subject, Event”.
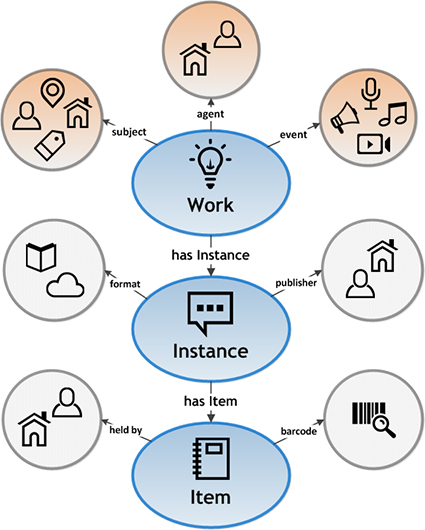
Abb.: Bibframe-Modell
Was ist der Unterschied zwischen BIBFRAME und MARC21?
Der Unterschied zwischen MARC21 (siehe Bericht 2 “Funktion und Aufbau von Bibliothekssystemen”) und BIBFRAME liegt darin, dass MARC21 ein in sich geschlossenes System BIBFRAME ein Beziehungssystem darstellt. Das MARC-Format dient der bibliografischen Beschreibung und fokussiert die eigenständige Ressource als Record. MARC fasst Information zum konzeptuellen Werk und seinem Träger zusammen, indem Zeichenketten für Identikation, Name, Thema etc. im Record angelegt werden. Für Institutionen und Nutzende außerhalb der MARC 21-Community bleiben die Daten unverständlich und nicht interpretierbar. BIBFRAME hingegen baut auf Beziehungen zwischen den Ressourcen. So gibt es Work-to-Work relationships, Work-to-Instance relationships oder Work-to-Agent relationships. Diese Beziehungen werden hergestellt, indem kontrollierte Identifikatoren für Dinge (people, places, languages, etc) verwendet werden. BIBFRAME nutzt das bereits im Record abgebildete Kontextwissen und stellt die Daten in einem komplexen Beziehungssystem zueinander.
Wo wird BIBFRAME bereits angewendet?
Hier gibt es eine Übersicht über Pilotprojekte.
Bei Alma (siehe Beitrag 3 “Weitere Bibliothekssysteme”) wird laut Dozent Sebastian Meyer folgender Status zur Nutzung von BIBFRAME angegeben:
“All bibliographic records in Alma can be viewed and exported as BIBFRAME and can be accessed via a unique URI.”
Zum BIBFRAME-Prototyp der Deutschen Nationalbibliothek gibt es eine entsprechende Nachricht des zuständigen Mitarbeiters für Datenformate:
“Jetzt wurde das Verfahren umgestellt auf eine zweistufige Konversion, nämlich von Pica+ nach MARC 21 (in der Version MARCXML), und dann weiter nach BIBFRAME. Für diesen zweiten Schritt wird die von der Library of Congress erstellte und durchgehend gepflegte Konversion “marc2bibframe2” (ein frei verfügbares Paket zur XML-Transformation, XSLT) verwendet. Erste interne Tests waren vielversprechend, so dass wir damit jetzt auch an die Öffentlichkeit gehen möchten.”
Und ist RiC das Zukunftsmodell für die Archive?
Ja, denn im Kontext der Archive wird künftig nämlich nicht BIBFRAME, sondern RiC (Records in Contexts) eine wichtige Rolle spielen. Das Interantional Council on Archives entwirft derzeit das konzeptuelle Modell dazu. Der neue Standard basiert auf Linked-Data-Prinzipien und möchte eine mehrdimensionale Erschliessung, also mehrfache Beziehungen zwischen Entitäten, ermöglichen.
Records in Contexts, or RiC, is a conceptual model and ontology for the archival description of records, designed by the Expert Group on Archival Description established by the International Council on Archives. The EGAD initially began work on the standard between 2012 and 2016, with a conceptual model and an ontology released for comment during 2016 and 2019. (Wikipedia)
Durch diese mehrdimensionale Erschliessung dürfte sich die Arbeitsweise der Achivar’innen künftig ändern, weil die Beziehungen der Daten neu gedacht werden müssen. Die bis anhin gängige, hierarchisch angelegte Archivierungspraxis würde damit hinfällig werden.
Der Artikel “Neue Wege in der archivischen Erschliessung” in der aktuellen Ausgabe von arbido, der Fachzeitschrift für Archiv, Bibliothek und Dokumentation bringt das so auf den Punkt: Heute müssen Archivnutzerinnen und -Nutzer, die beispielsweise im Archiv Informationen zu einer Person suchen, zuerst den Bestand und anschliessend die relevanten Dossiers identifizieren. Erst dann gelangen sie zu den für sie interessanten Unterlagen. Im RiC-Modell hingegen wird die gesuchte Person durch eine Entität repräsentiert. Diese Entität kann auf eine andere Entität verweisen, welche ausserhalb des eigenen Bestands vorhanden ist. Es ist deshalb möglich, innerhalb einer Netzstruktur die Beziehungen zwischen verschiedenen Entitäten aus unterschiedlichen Beständen zu analysieren. Die Suche nach relevanten Informationen kann auch ohne Sachkenntnisse über die Archivtektonik einfacher erfolgen. Die netzartige Darstellung von Informationen und die erweiterten Suchmöglichkeiten können dabei helfen, das bisher scheinbar verborgene Archivgut leichter zu finden.
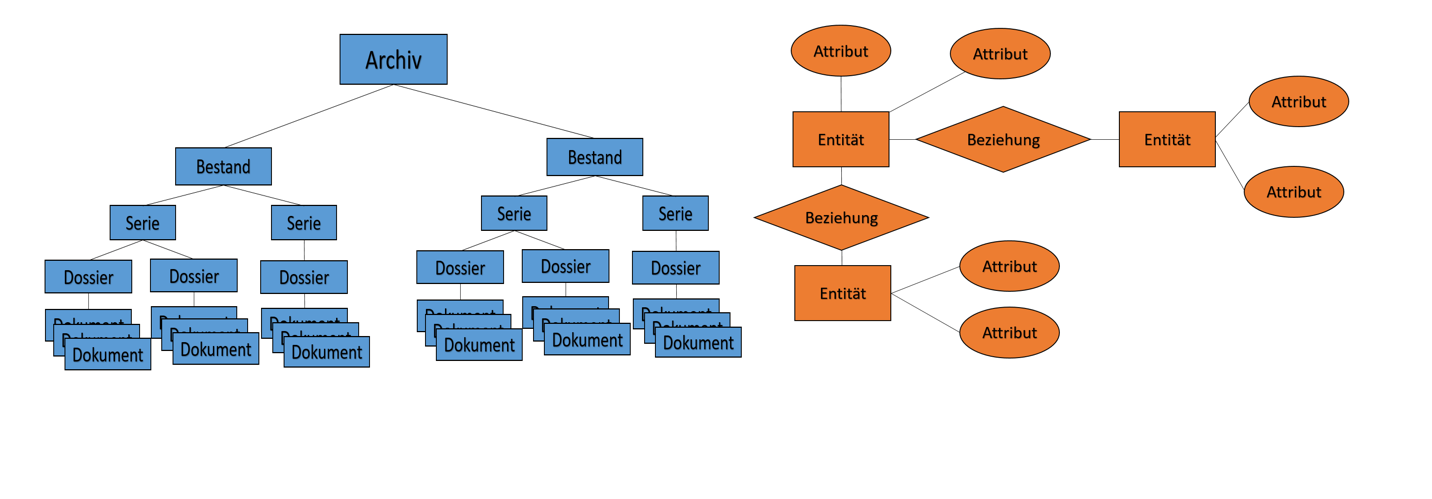
Abb.: Darstellung von Archivinformation mit ISAD(G) und RiC
Die 5 ISAD(G)-Stufen werden im RiC von insgesamt 22 Entitäten abgelöst, die das Archivgut und auch Aktenbildner, Funktionen usw. beschreiben. Die Entitäten werden mithilfe der Ontologie RiC-O5 weiter präzisiert. Sie können in unterschiedlichen Beziehungen miteinander stehen. Es entsteht dabei eine Netzstruktur von Entitäten, die aufeinander verweisen. Mittels dieser Linked Data Modellierung können die archivischen Metadaten genauer beschrieben und maschinenlesbar gemacht werden. Dies ermöglicht eine wesentlich flexiblere Strukturierung und eine bessere Darstellung von Entitäten in ihrem vielfältigen Kontext. (arbido 2020/4)
Der Umstieg von ISAD(G) auf RiC wird nicht nur mit Umdenken, sondern auch mit einem Systemwechsel und viel Aufwand verbunden sein. Aufgrund der Digitalisierung und Möglichkeit der Volltextsuche besteht jedenfalls ein grosser Nachholbedarf bei Archiven, die Bestände für andere Archive und Nutzer’innen online bereitzustellen. So sieht das übrigens auch David Gniffke in seinem Beitrag “Semantic Web und Records in Contexts (RiC)” im Blog Archivwelt. Gniffke spricht von einem paradigmatischen Wandel, weil etliche Argumente dafür sprechen, dass sich sowohl für Archivarinnen als auch für Nutzerinnen der Umgang mit Erschließungsdaten nachdrücklich verändern wird. Das wäre dann auch ganz im Sinn des Kodex ethischer Grundsätze für Archivarinnen und Archivare des Internationalen Archivrats (ICA):
„Archivarinnen und Archivare haben sich für die weitest mögliche Benutzung von Archivalien einzusetzen.“
ENSEMEN ist eine Arbeitsgruppe des Vereins Schweizerischer Archivarinnen und Archivare VSA-AAS, die an einer schweizerischen Ausprägung des neuen RiC-Standards arbeitet. Niklaus Stettler, Dozent an der FHGR, ist am Projekt beteiligt.
Wo wird RiC bereits angewendet?
Noch stehen RiC-Projekte am Anfang. Memoriav, der Verein zur Erhaltung des audiovisuellen Kulturgutes der Schweiz, betreibt MEMOBASE als Kernprodukt von Memoriav. Unter MEMOBASE 2020 erscheint am 2.7.2020 folgender Beitrag:
“Parallel zur intensiven Arbeit an der Datenvisualisierung setzt das Projektteam für die Erneuerung der Memobase auf ein neues Datenmodell, das als Dreh- und Angelpunkt für das Datenmanagement fungieren soll. Die Entscheidung fiel dabei auf den Records in Contexts (RiC) Standard, der darauf abzielt, alle aktuellen Standards für die Archivbeschreibung in einem zukünftigen verknüpften Datenmodell (RDF) zu vereinen. Dieses ermöglicht uns, von einem hierarchischen zu einem mehrdimensionalen Verständnis von Informationen überzugehen, das für audiovisuelle Aufzeichnungen viel besser geeignet ist. Diese Wahl erlaubt es uns auch, die Verbindung unserer Daten mit denen anderer Institutionen (Wikidata, GND, Geonamen usw.) in Betracht zu ziehen, um die Datenlage zu verbessern und die Daten auch anreichern zu können. Die für die Memobase angedachte Anwendung des noch in Entwicklung befindlichen RiC-Standards für die rund halbe Million Records und dementsprechend mehreren Millionen Triples ist nicht nur schweizweit, sondern auch international ein innovatives Vorhaben, dessen Umsetzung die Spezifikation des Standards international weiter vorantreiben wird und für diverse Kreise von grossem Nutzen sein wird.”
Un der von Dozent Felix Lohmeier empfohlenen Präsentation von Florence Clavaud zu RiC sind auf Folie 70 folgende mögliche Projekte mit Fokus auf Frankreich zu entnehmen:
- RiC will most probably be implemented by/within Social Networks and Archival Context (SNAC)
- Maybe, the SONAR(idh) project will use it
- The FranceArchivesportal may also implement RiC
- Same for the next version of ATOM software, and some software or projects of Docuteam company (vgl. Beitrag 2 “Weitere Archivinformationssysteme)
- RiC is already used at the Archives nationales de France ANF
Weiter zum Epilog.
tags: