BAIN?!
Fragen und Antworten zu Bibliotheks- und Archivinformatik
9: Discovery-Systeme und Suchmaschinen
by K.K.Buhler
SOLR & VUFIND
In diesem Beitrag werden die Suchmaschinen und Discovery-Systeme beleuchtet - jene Tools also, mit denen die aufbereiteten Datensätze durchsucht werden.
Was ist der Unterschied zwischen einem Discovery-System und einer Suchmaschine?
Der Unterschied lässt sich vielleicht mit Front- und Back-End eines Recherche-Portals beschreiben. So bestehen bibliothekarische Suchsysteme aus einer Nutzeroberfläche (Front-End) und der Datenbasis mit einem durchsuchbaren Datenbankindex im Hintergrund (Back-End). Das Discovery-System meint in der Regel das Front-End (z.B. VuFind), welches verschiedene Indices durch das Back-End (z.B. Solr) nutzt. Online-Bibliothekskataloge sind deshalb oft eine Kombination aus Discovery-System und Suchmaschine, die aufgrund der Suchanfrage (Query) der Nutzer’innen miteinander kommunizieren.
Discovery-System?
Discovery-Systeme sind bibliothekarische Suchsysteme, die auf Suchmaschinentechnologie beruhen. Die sind Bestandteil des Konzepts der Bibliothek 2.0 und sollen die bisherigen OPAC-Kataloge ergänzen oder gar ersetzen.
VuFind
Hier wird das weit verbreitete Discovery-System VuFind vorgestellt. VuFind ist ein von Bibliotheken für Bibliotheken entwickeltes Rechercheportal. Ziel von VuFind ist es, den Nutzer’innen die Suche und das Schmökern in allen Ressourcen der Bibliothek zu ermöglichen. Das Discovery-System ersetzt den herkömmlichen OPAC. VuFind ist Open Source, modular aufgebaut und erlaubt die Implementierung des Basissystems oder auch aller zusätzlichen Kompenenten. Das Discovery-System VuFind basiert auf der Suchmaschine Solr und stellt die Anfrage in dessen Suchindex.
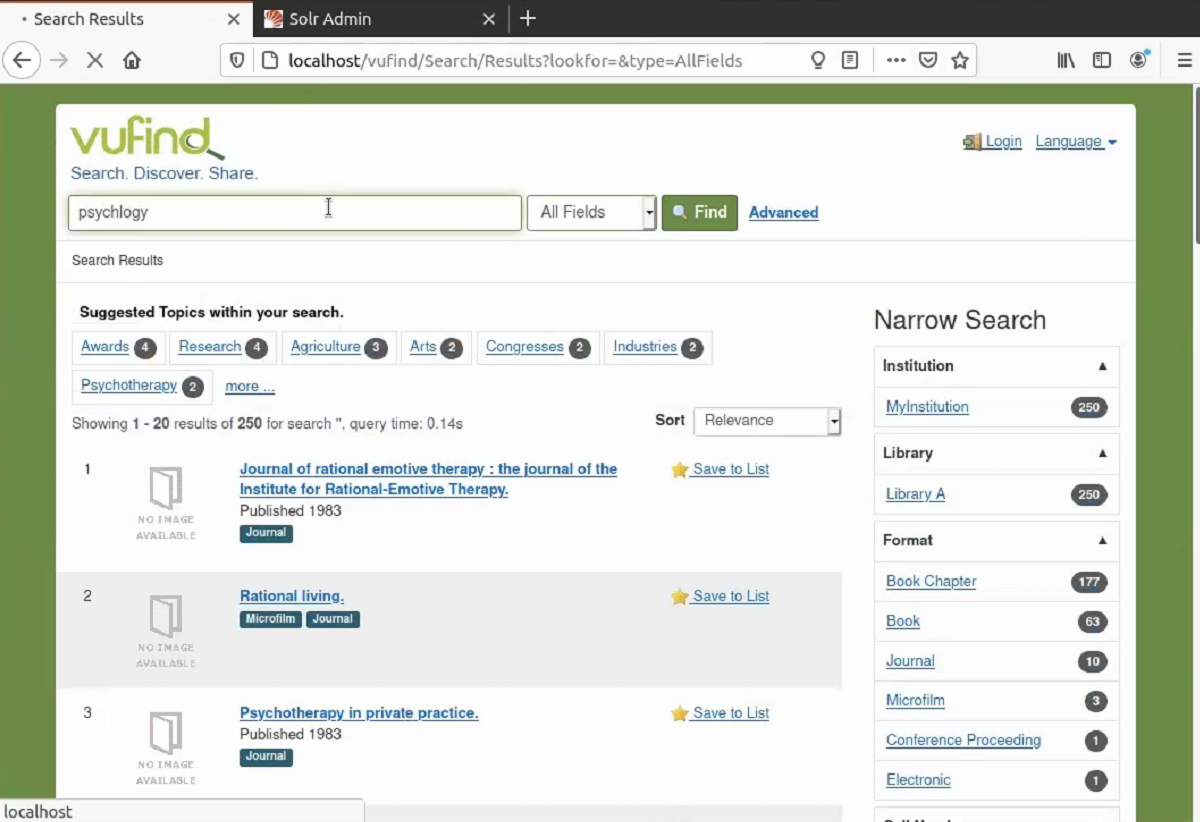
Abb.: VuFind-Suche nach dem Begriff “psychology” mit drei Ergebnissen
Welche weiteren Discovery-Systeme gibt es?
Hier eine Auflistung von kommerziellen und Open Source Produkten:
Kommerzielle Produkte:
- EBSCO Discovery Service
- Primo (ExLibris)
- Summon (Serial Solutions)
Open Source Produkte:
- VuFind (Villanova University Library)
- Lukida (Verbundzentrale des GBV)
- typo3find
- beluga core (modulare Erweiterung von VuFind)
An den wissenschaftlichen Bibliotheken in der Schweiz wurde durch die SLSP Swiss Library Service Platform das neue Rechercheportal swisscovery und damit auch das dazu gehörige Discovery-System Primo VE eingeführt.
Der jährliche Library Systems Report von Marshall Breeding im ALA Magazine lässt nicht nur die Bibliothekssysteme überblicken vgl. Beitrag 3, sondern führt auch Discovery-Systeme auf: Library System Report 2020. Weiter gibt diese Statistik aus demselben Haus einen guten Überblick zum internationalen Stand 2020: Charts 2020
Hier ein Überblick über VuFind-Installationen weltweit und ein Beispiel der TU Hamburg und UB Leipzig.
Suchmaschine?
Die gängige Definition von “Suchmaschine” nach Wikipedia:
Eine Suchmaschine ist ein Programm zur Recherche von Dokumenten, die in einem Computer oder einem Computernetzwerk gespeichert sind. Nach Erstellung einer Suchanfrage, oftmals durch Texteingabe eines Suchbegriffs, liefert eine Suchmaschine eine Liste von Verweisen auf möglicherweise relevante Dokumente, meistens dargestellt mit Titel und einem kurzen Auszug des jeweiligen Dokuments. Bei Suchmaschine denkt man heutzutage sofort an “Google”. Auch Betreiber von Websites nutzen Google in Form der Custom Search Engine (CSE), um Nutzer’innen schnell und einfach eine Suchfunktion für ihre eigenen Inhalte anzubieten. Doch ist das nicht die einzige – und für viele Website-Betreiber auch nicht die beste – Möglichkeit, den Nutzer’innen eine Volltextsuche anzubieten.
Solr
Eine Alternative für die www-basierte Google-Suchmaschine ist beispielsweise Solr. Die Website Bigdata Insider beschreibt Solr so:
Bei Solr, ausgesprochen “Solar”, handelt es sich um eine Open-Source-basierte Suchplattfom aus dem Apache-Lucene-Projekt. Die Software ist in Java geschrieben und stellt eine Vielzahl an Suchfunktionen bereit. Zur Kommunikation nutzt Solr das Hypertext Transfer Protocol (HTTP) und unterstützt Dateiformate wie XML, JSON oder PDF. Bei der Suche mit Solr werden typischerweise die folgenden vier Schritte nacheinander durchlaufen:
1. Indizierung
2. Abfragen
3. Mapping
4. Darstellung und Sortierung der Ergebnisse
Solr hat zwar eine integrierte Suchoberfläche, aber diese ist nur zu Demo-Zwecken gedacht. Entsprechend sieht die Benutzeroberfläche durch Anwendung von Kürzeln eher technisch aus. Die Dozierenden Lohmeier und Meyer empfehlen das offizielle Handbuch zu Solr, das ein gutes Tutorial (ca. 2 Stunden) beinhaltet: Solr-Tutorial
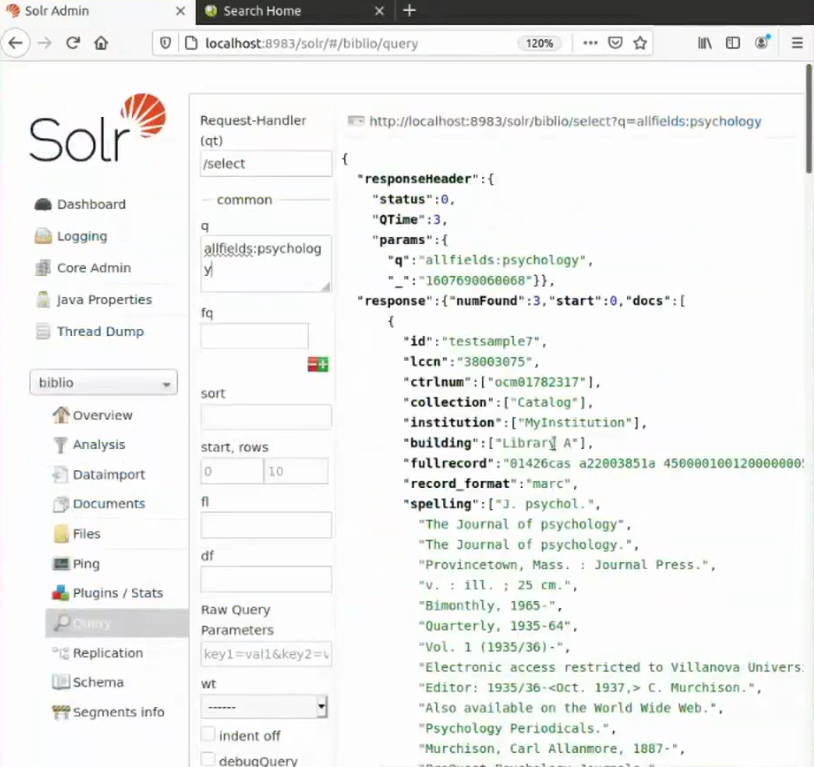
Abb.: Solr mit Query-Funktion (q)
Welche weiteren Suchmaschinen gibt es im Bibliotheks- und Archivbereich?
Bei Apache Lucene handelt es sich um eine Programmbibliothek, die von der Apache Software Foundation veröffentlicht wird. Sie ist Open Source und für jeden kostenlos zu benutzen und zu verändern. Ursprünglich hat man Lucene komplett in Java geschrieben, inzwischen gibt es aber auch Portierungen in andere Programmiersprachen. Mit Apache Solr und Elasticsearch gibt es mächtige Erweiterungen, die der Suchfunktion noch mehr Möglichkeiten geben.
Eigene Suchmaschine vs. Google & Co.?
Zusammenfassend: Warum will man also eine eigene Suchmaschine bauen, wenn es doch Google, Bing oder andere Search Engines gibt? Während Google & Co. auf Information aus dem World Wide Web beschränken, können Suchmaschinen wie Lucine, Solr oder Elasticsearch in einem beliebigen Szenario angewendet und für einen bestimmten Zweck konfiguriert werden. Der Vorteil in der eigenen Suchmaschine liegt demnach in der individuellen Anpassungsfähigkeit auf spezifische Wünsche, die beispielsweise Bibliothekskataloge mit sich bringen.
Was ist der Unterschied zwischen einem Suchindex (Solr) und einer Datenbank (MySQL)?
| Solr | MySQL |
|---|---|
| flache Dokumente | relationale Datensätze |
| lexikalische Suche | reiner Glyphenvergleich |
| keine Konsistenzprüfung | Transaktionssicherheit |
| statische Daten | veränderliche Daten |
| > Retrieval (Suche) | > Storage (CRUD) |
Tabelle: Unterschied Solr und MySQL, Quelle: Unterrichtsmaterial BAIN
Ein flaches Dokument enthält lediglich indexierte Objekte, die mehrere Eigenschaften haben können, aber in keiner Beziehung zu anderen Objekten steht. In relationalen Datensätzen hingegen können Beziehungen abgefragt werden, was bei der Anzeige der Ergebnisse Vorschläge zu “Ähnlichem” erlaubt. Daher beinhaltet die Abfrage von Solr eine lexikalische Suche, eine Begriffsuche. Bei MySQL wird ein Vergleich von Daten angestellt, ausgelöst durch einen Term/mehrere Terme und Suchoperatoren bei der Sucheingabe. Als Nachteil kann bei Solr angesehen werden, dass die Daten statisch vorliegen. Es ist keine Aktualisierung der Daten möglich, es können nur Kopien angelegt werden. Bei MySQL sind die Daten veränderlich, was weniger zu Doppeleinträgen (Dubletten) führt. So findet denn Solr im “Retrieval”, also der Suche Anwendung, während MySQL sich eher für Storage, also für eine Datenverwaltung anbietet. CRUD steht für Create, Read, Update, Delete. Das Ziel ist dabei eine persistente und konsistente Datenverwaltung.
Wie geheimnisvoll ist das Relevance Ranking der Suchergebnisse?
Das Relevance Ranking mag geheimnisvoll erscheinen, ist am Ende aber eine subjektive Einstellung, mit der die Suchergebnisse beeinflusst werden können. Eine Personalisierung der Suchergenisse ist wenig sinnvoll, da diese kaum wiederholbar ist und sehr subjektive Resultate erzielt. Die Expertensuche sieht spezifische Feldersuche vor, wodurch die voreingestellte Gewichtung wegfällt.
Die entscheidende Frage ist: Wie sollen die Suchfelder gewichtet werden, um die Suchergebnisse befriedigend anzuzeigen? Wer ist die Hauptnutzungsgruppe? Die Gewichtung kann entsprechend anpasst werden, wobei die Anwendung empirisch ausprobiert werden muss.
In VuFind können einzelne Felder gewichtet werden. So haben Multitplikationsfaktoren schliesslich Einfluss auf das Ranking und zeichen die Suchergebnisse entsprechend an. Die Suche in VuFind kann im Terminal als Logeintag mitverfolgt werden. In der unten angefügten Abbildung ist ersichtlich, wie hier beispielsweise die Gewichtung der abgesuchten einzelnen Titel-Felder vorgenommen wurde. So wird der Kurztitel mit 750 am höchsten gewichtet, dann folgt der “unstemmed” Volltitel mit Gewichtung 600 etc. Die Anlage von verschiedenen Titel-Feldern (short, full, unstemmed, alternate, …) und deren individueller Gewichtung erlaubt schliesslich ein Relevanz Ranking.
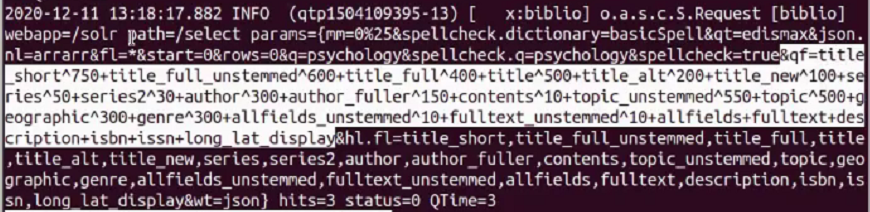
Abb.: VuFind-Logausgabe im Terminal zeigt Gewichtung der unterschiedlichen Titelfelder
Die anpassbare Gewichtung des Relevanz Ranking stellt denn auch eine wertvolle Eigenschaft eines Katalogs dar.
Was soll der perfekte Katalog können?
Wann ist etwas “perfekt”? Für wen? Perfekt meint in anderen Worten auch einwandfrei, fehlerfrei, fehlerlos, untadelig, tadellos, meisterhaft, mustergültig, vollkommen, vollendet, lupenrein, richtig, korrekt, ideal … Die Frage nach dem perfekten Katalog ist denn also eine grosse Frage, die nicht oder nur ansatzweise beantwortet werden kann.
Da das Perfekte wohl am besten auf einen bestimmten Nutzer’innenkreis hin definiert und beschränkt werden kann scheint mir diese Folgefrage sehr wichtig:
- Was sind die Bedürfnisse der Nutzer’innen?
Wenn diese Bedürfnisse geklärt sind, können damit verschiedene Anforderungen an den Katalog gestellt werden. In dieser Hinsicht wäre eine grösstmögliche Flexibilität und Anpassungsfähigkeit der Konfiguration ein grosser Pluspunkt. Bei VuFind können die Such- und Facetten-Einstellungen konfiguriert werden, was als äusserst interessante Funktion bewertet werden darf: Video “Configuring Search and Facet Settings” Damit kann eine nutzerorientierte Oberfläche bereitgestellt werden.
Individuelle Bedürfnisse könnten sein:
- schneller, einfacher Einstieg mit Möglichkeit der Differenzierung und Verfeinerung der Suche
- Discovery-System soll Informationsverlust alle Daten abbilden können, welche die Suchmaschine zur Verfügung stellt
- Transparenz bei der Definition von relevanten Ergebnissen, allenfalls Anpassungsmöglichkeit
- sprachgesteuerte Suche, um mühseliges Tippen zu vermeiden (v.a. an mobilen Devices ein Bedürfnis)
Die sprachgesteuerte Suche könnte in Zukunft angesagt sein und wäre eine technische Innovation. In der Tat bietet der neue Bibliotheks-Onlinekatalog “swisscovery” die sprachgesteuerte Suchfunktion an!

Abb.: Swisscovery-Suchschlitz mit Mikrofon-Icon (Chrome Browser)
Mit Klick auf Mikrofon-Icon beim Suchschlitz wird die sprachgesteuerte Suchfunktion aktiviert - und funktioniert auf dem Chrome-Browser einwandfrei.
 Abb.: Sprachgesteuerte Suche bei Swisscovery
Abb.: Sprachgesteuerte Suche bei Swisscovery
Für eine effiziente und effektive Suche von Information wird Wissen über Informationsressourcen, Recherchestrategien, -methoden und -techniken benötigt. Diese Informationskompetenz ist Voraussetzung, dass die Informationsarbeit der Recherche autonom erfolgt. Die ganze Informationsarbeit allerdings selbst durchzuführen, ist kaum noch möglich und wird zu einem großen Teil an andere Menschen, z.B. Bibliothekar/innen, und zunehmend auch an Suchmaschinen und Discovery-Systeme delegiert. Durch die Delegation kommt es zwangsläufig zu einem Verlust an informationeller Autonomie, der im Allgemeinen durch Vertrauen zu Personen und Systemen kompensiert wird. Gilt dies auch für Suchmaschinen und Discovery-Systeme, z.B. für das Relevance Ranking?
Diesen weiterführenden Gedanken geht Klaus Niedermayr in diesem Dokument nach: Gefährden Suchmaschinen und Discovery-Systeme die informationelle Autonomie? Anhand von Beispielen deutet Niedermayr an, dass Vertrauen in Suchmaschinen und Discovery-Systeme durch Maßnahmen der Transparenz, Partizipation und Interaktivität forciert werden könnte.
Weiter zu Beitrag 10 “Linked Data”.
tags: