BAIN?!
Fragen und Antworten zu Bibliotheks- und Archivinformatik
6: Repository-Software für Publikationen und Forschungsdaten
by K.K.Buhler
OPEN DATA & ANWENDUNGEN
In diesem Beitrag geht es um den Umgang mit Forschungsdaten und deren Ablagesystem. Bevor hier auf die Ablage, das “Repository”, eingegangen wird, gilt es erst den Begriff “Open Data” zu klären, der im Umgang mit Forschungsdaten wichtig ist.
Was ist der Unterschied zwischen Open Source, Open Access und Open Data?
Kurz: Während Open Source einen freien Zugang auf einen Quellcode einer Software bezeichnet, bezieht sich der freie Zugang bei Open Access auf Publikationen und bei Open Data auf Forschungsdaten.
| Open Source | Quellcode |
| Open Access | Publikationen |
| Open Data | Forschungsdaten |
Tab.: Begriffsklärung über Zuschreibung zu freiem Zugang
Nun etwas ausführlicher:
Open Source?
Open Source meint also die freie Verfügbarkeit von Software-Quellcodes, welche im Rahmen von Open-Source-Lizenzmodellen unentgeltlich genutzt und verändert werden können. Der Begriff entstand 1998 zeitgleich mit der damals gegründeten Open Source Initiative (OSI) und prägt seitdem das Bild der Softwareentwicklung. Das Open-Source-Konzept unterscheidet sich grundsätzlich von der proprietären, kommerziellen Software. Denn um eine proprietäre Software zu nutzen, zu verteilen bzw. neu zu verteilen oder zu modifizieren, ist eine Genehmigung des Softwareeigentümers oder Erwerb der Software erforderlich.
Es gibt vier charakteristische Merkmale der Open-Source-Software:
- Lizenz der Software, die eine weitere Nutzung erlaubt
- nicht-kommerzielle Einstellungen
- hoher Grad an Kollaboration bei der Programmentwicklung
- starke räumliche Verteilung der Entwickler
Beispielsweise funktionieren die Projekte Mozilla und Linux nach dem Prinzip der Open Source. Das weltweit wohl bekannteste und erfolgreichste Beispiel ist die Enzyklopädie Wikipedia, an welcher jede’r mitarbeiten kann und so zur größten Wissensammlung der Welt wurde.
Open Access?
Open Access meint den freien Zugang zu wissenschaftlicher Literatur und anderen Materialien im Internet. Ein wissenschaftliches Dokument unter Open-Access-Bedingungen zu publizieren, gibt jedermann die Erlaubnis, dieses Dokument zu lesen, herunterzuladen, zu speichern, es zu verlinken, zu drucken und damit entgeltfrei zu nutzen. Darüber hinaus können über freie Lizenzen den Nutzern weitere Nutzungsrechte eingeräumt werden, welche die freie Nach- und Weiternutzung, Vervielfältigung, Verbreitung oder auch Veränderung der Dokumente ermöglichen können. Unter dem Druck der steigenden Preise für wissenschaftliche Publikationen bei gleichzeitig stagnierenden oder schrumpfenden Etats in den Bibliotheken während der Zeitschriftenkrise bildete sich seit Beginn der 1990er Jahre eine internationale Open-Access-Bewegung. Die zentrale Forderung dieser Bewegung ist, dass wissenschaftliche Publikationen als Ergebnisse der von der Öffentlichkeit geförderten Forschung dieser Öffentlichkeit wiederum kostenfrei zur Verfügung gestellt werden sollen. Bei der Umsetzung gibt es verschiedene Strategien, die mit “goldenem, grünem, grauem oder bronzenem Weg” bezeichnet werden, welche die Einhaltung der Open-Access-Bedingungen differenziert einstufen.

Abb.: Open-Access-Logo der Public Library of Science
Open Data?
Laut Wikipedia: Als Open Data (aus englisch open data ‚offene Daten‘) werden Daten bezeichnet, die von jedermann zu jedem Zweck genutzt, weiterverbreitet und weiterverwendet werden dürfen. Einschränkungen der Nutzung sind nur erlaubt, um Ursprung und Offenheit des Wissens zu sichern, beispielsweise durch Nennung des Urhebers oder die Verwendung einer Share-alike-Klausel. Unter offene Daten sind sämtliche Datenbestände von staatlichen Stellen gemeint, wie zum Beispiel:
- Lehrmaterial
- Geodaten
- Statistiken
- Verkehrsinformationen
- wissenschaftliche Publikationen
- medizinische Forschungsergebnisse
- Hörfunk- und Fernsehsendungen
Darüber hinaus können auch Daten aus privatwirtschaftlich agierender Unternehmen, Hochschulen sowie Non-Profit-Einrichtungen als Open Data gelten. Hervorzuheben ist, dass offene Daten keine personenbezogenen Daten oder dem Datenschutz unterliegende Daten beinhalten dürfen.
Opendata.ch ist die Schweizer Sektion der Open Knowledge Foundation, welche sich für die freie Nutzung aller nichtpersönlichen Daten einsetzt. Die Sektion definiert Open Data so:
Daten öffentlich, frei verfügbar und nutzbar zu machen für mehr Transparenz, Mitwirkung und Innovation — das ist Open Data.
Das Konzept hinter Open Data kann bis auf das Internationale Geophysikalische Jahr 1957/58 zurückgeführt werden. Damaliges Ziel war, durch die Einrichtung von Datenaustauschzentren und die Standardisierung von Metadaten den Austausch und die Nutzung wissenschaftlicher Daten zu erleichtern. Daten, die den Kriterien von Open Data genügen sollen, müssen strukturiert und maschinenlesbar zur Verfügung gestellt werden, so dass sie sich filtern, durchsuchen und von anderen Anwendungen weiterverarbeiten lassen können. Daten von Regierungsstellen zum Beispiel liegen allerdings oft als PDF vor und sind somit nicht ohne Probleme weiterzuverarbeiten.
Die Open-Data-Bewegung fordert nicht nur den freien Zugang zu Daten, sondern generiert diese auch selber. Ein Beispiel dafür ist OpenStreetMap. Befürworter behaupten, dass durch das Open Data Konzept auch eine demokratischere Gesellschaft möglich sei. Die seit 2007 bestehenden Konferenzen der re:publica thematisieren das Web 2.0, speziell Weblogs, soziale Medien und die digitale Gesellschaft. Rob McKinnon sagte bei einem der Vorträge, dass „der Verlust des Datenprivilegs zu neuen Machtstrukturen innerhalb einer Gesellschaft führen könne“. Open Data stellt demnach eher eine Bewegung dar, die politisch agiert.
Was wird unter Repository-Software verstanden?
In der Software-Entwicklung ist ein Repository ein zentraler Dateispeicherort. Um verschiedene Versionen von Dateien abzuspeichern wird ein Versionskontrollsystem verwendet. Während die zentrale Ablage auf einer lokalen Maschine für Einzelpersonen konfiguriert wird, erlaubt die Ablage auf einem Server den Zugang für viele Nutzer’innen. Unter Repository-Software wird demnach eine Software verstanden, die Daten zentral speichert und nutzbar macht.
Welche Repository-Software gibt es?
Einen Überblick gibt auch hier noch einmal die Statistik zu Open-Access-Repositorien von OpenDOAR, die eine weltweite Übersicht gibt:
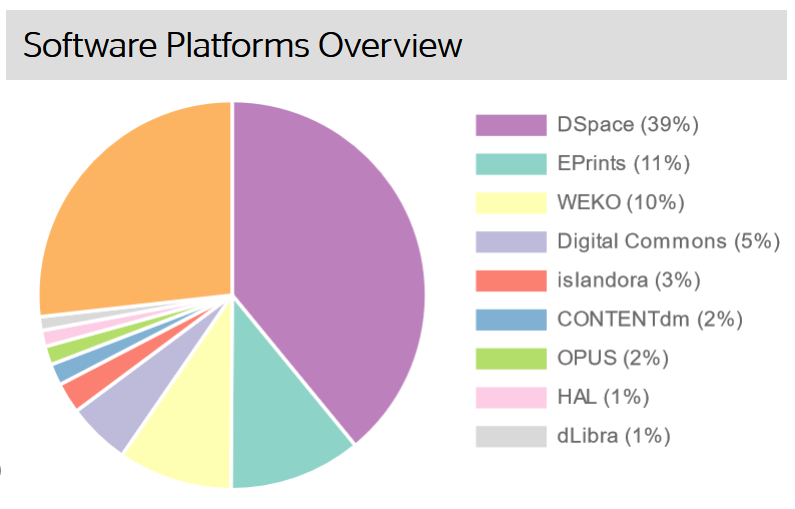
Abb.: Verschiedene Repository-Software-Plattformen
Hier sind einige Repository-Softwares aufgelistet und verlinkt:
DSpace ist mit 39% die häufigst genutzte Software Plattform. DSpace ist ein Repository, das sich besonders für Publikationen und Forschungsdaten eignet. Hier ein DSpace-Werbevideo.
Zenodo wird vom CERN betrieben. Es nimmt Forschungsdaten und Publikationen auf, ist kostenfrei und zudem kann auf der Plattform eine eigene Community eröffnet werden. Weiter ist ein Upload von riesigen Datenmengen möglich.
TUHH Open Research (DSpace-CRIS) ist ein Repositorium für Open-Access-Publikationen, für Forschungsdaten und ab 2019 auch ein Forschungsinformationssystem.
Und wie werden diese Forschungsinformationssysteme angewendet?
Die Statistik zu Open-Access-Repositorien von OpenDOAR gibt einen Eindruck zur Anwendung von digitalen Open-Access-Ressourcen. Zum Beispiel werden in der folgenden Grafik Repository-Inhalte dargestellt. An dritter Stelle werden Bücher erwähnt. Zudem decken sich einige Inhalte mit den unter Open Data erwähnten Medien:
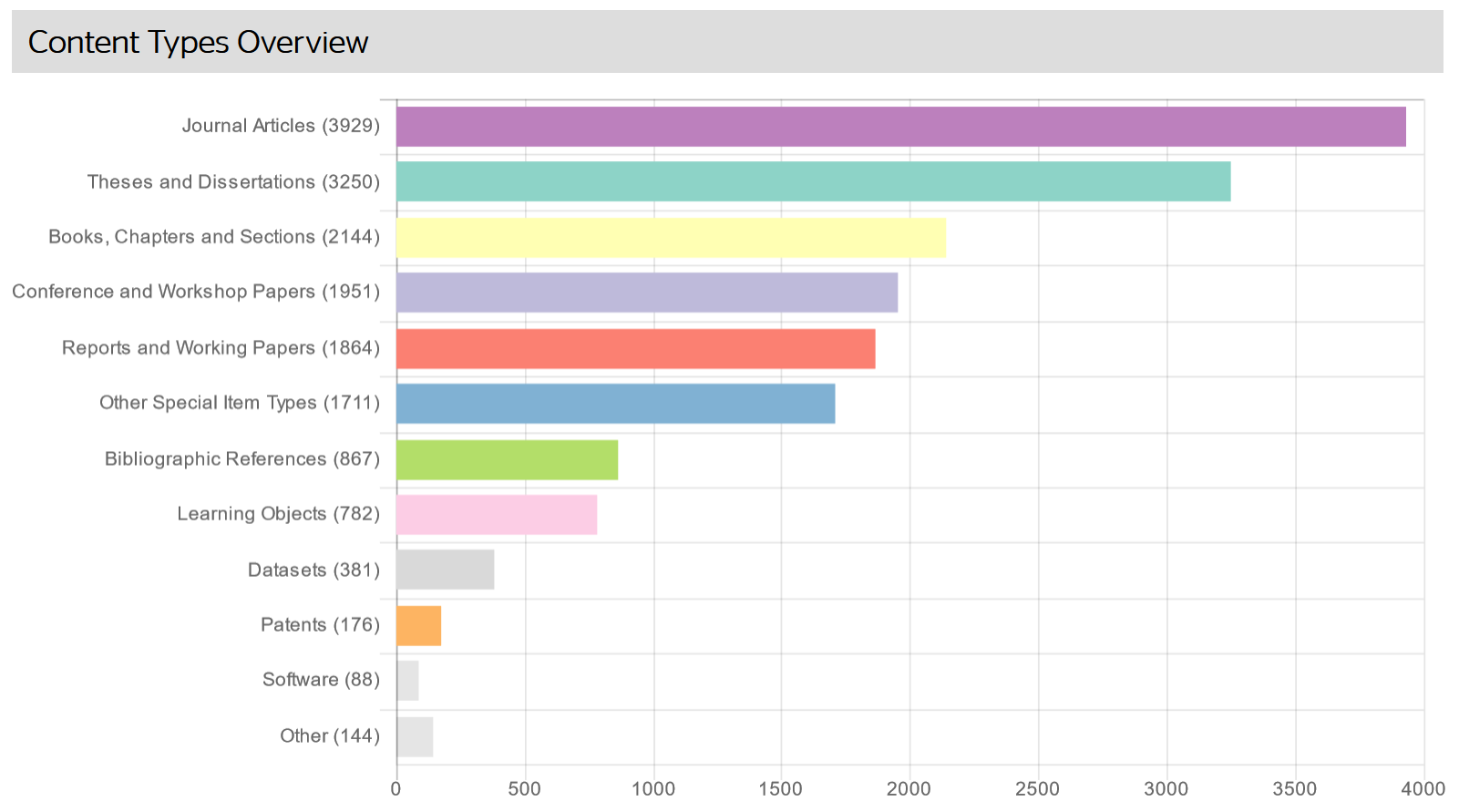
Abb.: Überischt über Repository-Inhalte
Damit die Forschungsdaten austauschbar sind, müssen Standards eingehalten werden. Dazu haben Dr. Sonia Ackermann Krzemnicki und Dr. Bernd F. Hägele Informationen, Analysen und Empfehlungen ausgearbeitet: Die Standardisierung von Forschungsinformationen an Schweizer universitären Hochschulen (2016)
Entsprechend werden Forschungsinformationssysteme oft an den Universitäten eingeführt, um die Daten zusammenzuführen und Berichte erstellen zu können. Forschungsinformation beinhaltet denn auch Berichterstattung über Forschende, Drittmittelprojekte, Patente und vieles mehr. Hier ein Verzeichnis von Forschungsdaten-Repositorien von re3data.
Since its launch in 2012, re3data has become the resource of information about research data repositories. It indexes and provides extensive information about more than 2450 research data repositories. Universities and research centres register their institutional, disciplinary and interdisciplinary research data repositories in re3data to enable researchers, funding bodies, publishers and scholarly institutions to select appropriate repositories for storage and search of research data. As a service of DataCite, hosted and run by the KIT Library, re3data enhances accessibility and visibility of research data repositories from all over the world.
Im universitären Umfeld wird von CRIS Current Research Information System gesprochen.
A current research information system (CRIS) is a database or other information system to store, manage and exchange contextual metadata for the research activity funded by a research funder or conducted at a research-performing organisation (or aggregation thereof). CRIS systems are also known as Research Information Management or RIM Systems (RIMS).
EuroCris, The International Organisation for Research Information, beantwortet hier die Frage “Why does one need CRIS?”.
Weiter zu Beitrag 7 “Schnittstellen nutzen und Metadaten austauschen”.
tags: